iOS App启动的奥秘
随着智能手机,平板在中国普及率的上升,人们越来越依赖移动设备进行娱乐、消费,由此催生出的App更是层出不穷。根据苹果2019年2月的数据,目前AppStore上的App数量已经超过220万,比2018年同期增长了近10万个App。2015年6月到2016年6月可谓是App发展的高速时期,仅仅一年时间就增长了50万个App;同时期也是中国互联网+的黄金时期,各种创业项目,平台推出了各式各样的移动App产品。
随着App的爆发式增长,我们越来越清晰地发现, 大多数App是无法长期停留在用户手机里的, 而今天这篇文章,我们将从一个开发者的角度来思考:如何提升用户体验,让我们的App在同类产品中脱颖而出,最终能够长期稳定的存在于用户手机之中。
每当我们说到用户体验,我们往往想到的是优化界面,交互方式等。这些固然重要,但这更多的是产品和UX的职责。作为开发,我们需要考虑他们无法完成的,更有技术导向的事情,比方说:优化App的启动流程。
为什么要考虑App的启动时间
这个问题乍看上去有点废话连篇的意思,哪个用户不希望App能够飞速的打开? 哪个公司不希望自己的App能有这样好的性能?但这个问题,其实质是希望帮助开发人员理顺业务、服务的初始化思路,以及构建项目的方式。
在展开来说之前,我们需要定义下什么是App的启动:
通俗来讲,就是从用户点击App图标开始,到看到第一个页面的时间间隔。
细分来看,App的启动分两种:冷启动和热启动。- 冷启动:App启动前,内核没有为它分配相应的进程。
- 热启动:App冷启动后,用户将App退出至后台,再进入的过程。
热启动没什么好说的,能做的通用的事情非常少。App从后台回来直接进入AppDelegate生命周期函数,剩下的就是App自身的业务逻辑,如果要优化,也仅是业务上的优化,恢复数据,做一些同步。所以本篇我们只展开讲冷启动(后文将用启动代替冷启动)的流程和优化。BTW: 笔者建议先从热启动开始优化,毕竟大部分的性能瓶颈都在自家代码里。
App启动步骤概览
从大方向讲,App启动步骤分为三个阶段:
- 从系统 exec 函数调用到我们App的 main 函数为止 (main函数之前)
- main 函数执行之后
- 首屏渲染结束(至第一个界面的viewDidAppear,Nib loading)
整个流程如下:

概括来讲:内核先将我们的App加载进内存,之后加载一个“中间件”: dynamic loader(简称:dyld)。之后dyld会负责分析App的Mach-O文件以加载所需的dynamic libraries。之后利用Rebasing和Binding修正内部和外部指针指向。最后加载runtime组件,runtime组件加载好后就会向需要初始化的object发送消息,开始初始化。 至此,main函数之前的步骤结束。之后的流程就是我们耳熟能详的生命周期了,App开始在AppDelegate里面初始化我们自定义的服务以及渲染首屏等。
Crash Course (名词速成班)
相信你看到这里或多或少已经对其中的一些名词感到陌生甚至”讨厌”了。这里面可能除了runtime,其他的你都没接触过。所以,这一小节我们针对上述流程涉及到的名词加以解释,并帮助大家扩充下底层知识,更好的理解main函数之前发生的事情。
内核
内核是操作系统的核心。iOS和OS X使用的都是XNU内核。在这里,我们不需要知道XNU内核的详细架构,只需要知道它的功能即可,例如:提供基础服务,像线程,进程管理,IPC(进程间通信),文件系统等等。
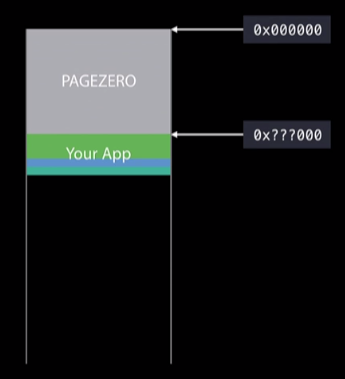
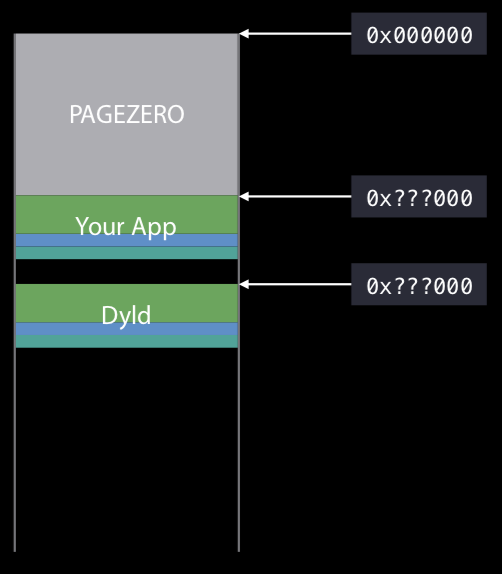
上图阐述了内核是如何加载我们的App到进程中的。在这幅图里有两个关键点:
- PAGEZERO是怎么回事?
- 为什么我们的App起始位置是不确定的?
这就要涉及到下一个知识点:ASLR。
ASLR(地址空间布局随机化) + Code Sign
简单来说,就是当应用映射到逻辑地址空间的时候,利用ASLR技术,可以使得应用的起始地址总是随机的,以避免黑客通过起始地址+偏移量找到函数的地址。ASLR和Code Sign是iOS两种主要的安全技术。相信大家对Code Sign并不陌生,在底层上进行code sign的时候,加密哈希是针对Mach-O的每一个page,这就保证了dyld在加载Mach-O的时候可以确保单个page不被篡改。
那PAGEZERO的作用又是什么呢?当系统利用ASLR分配了随机地址后,从0到该地址的整个区间会被标记为不可访问,意味着不可读,不可写,不可被执行。这个区域的大小苹果给出了官方的解释:
- 针对32位进程,至少4KB
- 针对64位进程,至少4GB
这块区域可以帮助我们捕获任意的空指针和指针截断。(例如:64位指针转32位的时候)
虚拟内存
理解了虚拟内存能够更好地帮助我们理解iOS内部机制。首先,现有的操作系统大都使用逻辑地址和物理地址这两个概念。逻辑地址可以理解为是虚拟地址,为的是”欺骗App”;但经过硬件和软件的配合,逻辑地址可以被映射到实实在在的物理地址上。
逻辑内存是被分页的,就像一整块蛋糕被分成多个小块一样。然后通过页表,映射到物理内存。物理内存是被分为很多帧的,和逻辑内存的页相对应。(页面和帧的对应关系主要是通过页表来保存)
总的来说,逻辑地址空间(虚拟内存)大大提高了CPU的使用效率,使得多个程序可以被同时、按需加载进内存。
iOS中,每一个进程都是一个逻辑地址空间,并且同时映射到物理内存上。这种映射不只是一对一关系,还可以是一对0,多对一。 当逻辑内存地址在物理内存上没有对应的地址时,就会发生Page Fault错误。这时候内核就会停止当前线程,分配一块物理内存给当前的逻辑地址;如果我们有两个进程运行在不同的逻辑地址空间,它们是可以同时映射到同一物理内存的,这时候就需要它们share部分的RAM了。
那么问题来了,既然两个进程的某些逻辑地址空间可以同时映射到相同的物理地址,那么如果它们一方需要修改该地址内容的话,该如何是好呢?这就需要介绍下iOS的Copy-On-Write(COW)机制了。
当一个进程试图向DATA page写入数据时,内核会立刻创建一个拷贝,并映射到另一个物理RAM
至于什么是DATA page, 我们稍后在Mach-O章节介绍。
当Copy-On-Write发生的时候,会产生dirty page, 与之相对的则是clean page。Clean page是那种内核可以之后从磁盘恢复的拷贝;而dirty page则包含了进程信息,无法被其他进程重用。

图中RAM 3所在的page就是一个dirty page。
在dyld章节我会再次提到clean page和dirty page,着重讲解dyld是如何通过修改Mach-O的__Data段,从而产生dirty page。
Mach-O
Mach-O,全称是Mac object file format, 是一种文件类型。哪些文件是Mach-O呢?
- Exectuable: 例如我们App bundle下的二进制文件
- Dylib: 动态库,好比Windows下的.dll
- Bundle: 指的是无法被链接,只能使用dlopen加载的动态库,例如Mac平台下的plug-ins
- Image: 以上三个
- Framework: 包含资源文件、头文件等的dylib
段(Segments)
Apple的Mach-O文件可以分为三大部分:
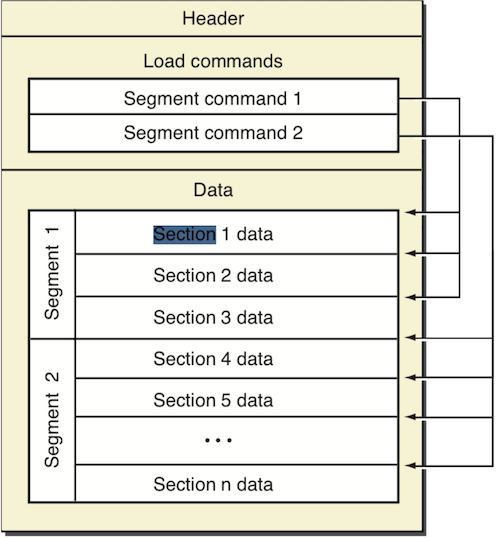
- Header: 头部, 包含可执行的cpu架构,文件类型等,例如arm64,x86;MH_EXECUTE。(如果合并过架构,则会是Fat Header)
- Load commands: 加载命令,包含文件的组织架构和在虚拟内存中的布局方式
- Data: 数据,包含load commands中需要的各个段(segment)的数据,每一个Segment的大小都是Page的整数倍。
Data部分示意图:
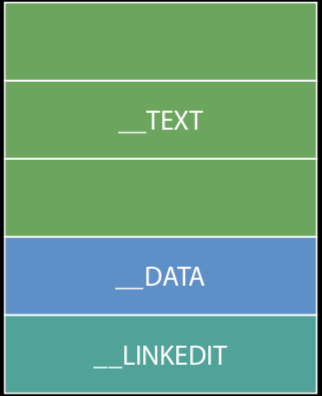
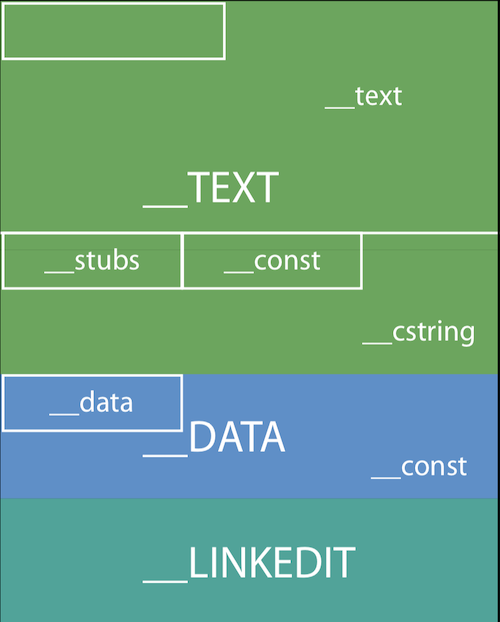
上例中,TEXT段大小是3页,DATA和LINKEDIT各是一页。Page的大小取决于硬件的架构,例如在arm64
架构下,每页是16KB;其余架构下每页是4KB。
Data部分包含哪些segment呢?绝大多数MachO包括以下三段:
- __TEXT: 代码段,只读,包括函数,和只读的常量,例如C字符串,上图中类似__TEXT, __text的都是代码段
- __DATA: 数据段,读写,包括可读写的全局变量, 静态变量等,上图中类似__DATA, __data都是数据段
- __LINKEDIT: 如何加载程序, 包含了方法和变量的元数据(位置,偏移量),以及代码签名等信息。
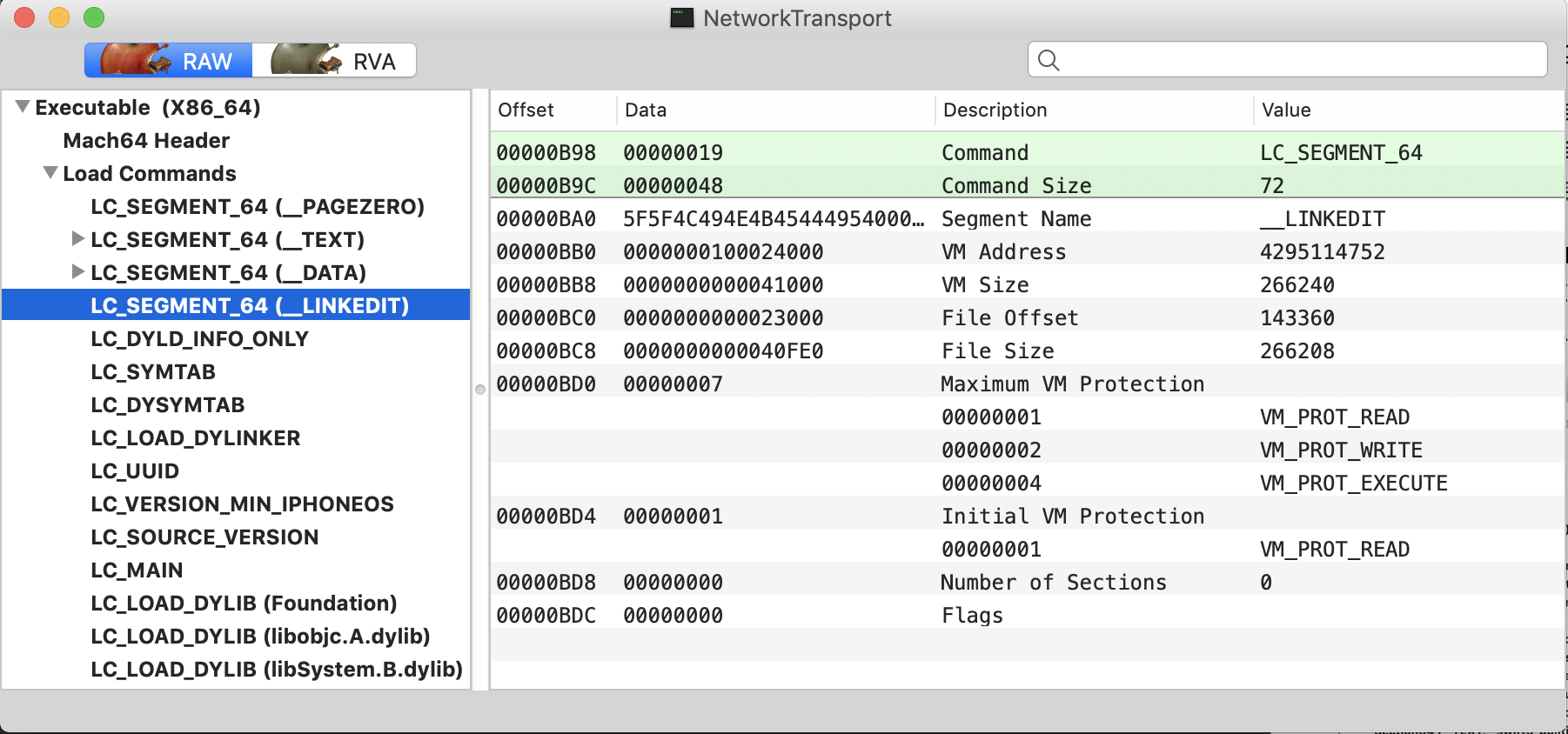
下图是我个人项目NetworkTransport的Mach-O文件布局: 从图中可以清晰的看到__TEXT和__DATA. 那__LINKEDIT去哪里了呢?据我观察__LINKEDIT似乎被隐藏了,但是其存储的元数据却是可见的,例如下图中笔者选中的Dynamic Loader Info一栏,Rebase的信息一览无余的展现在我们面前。
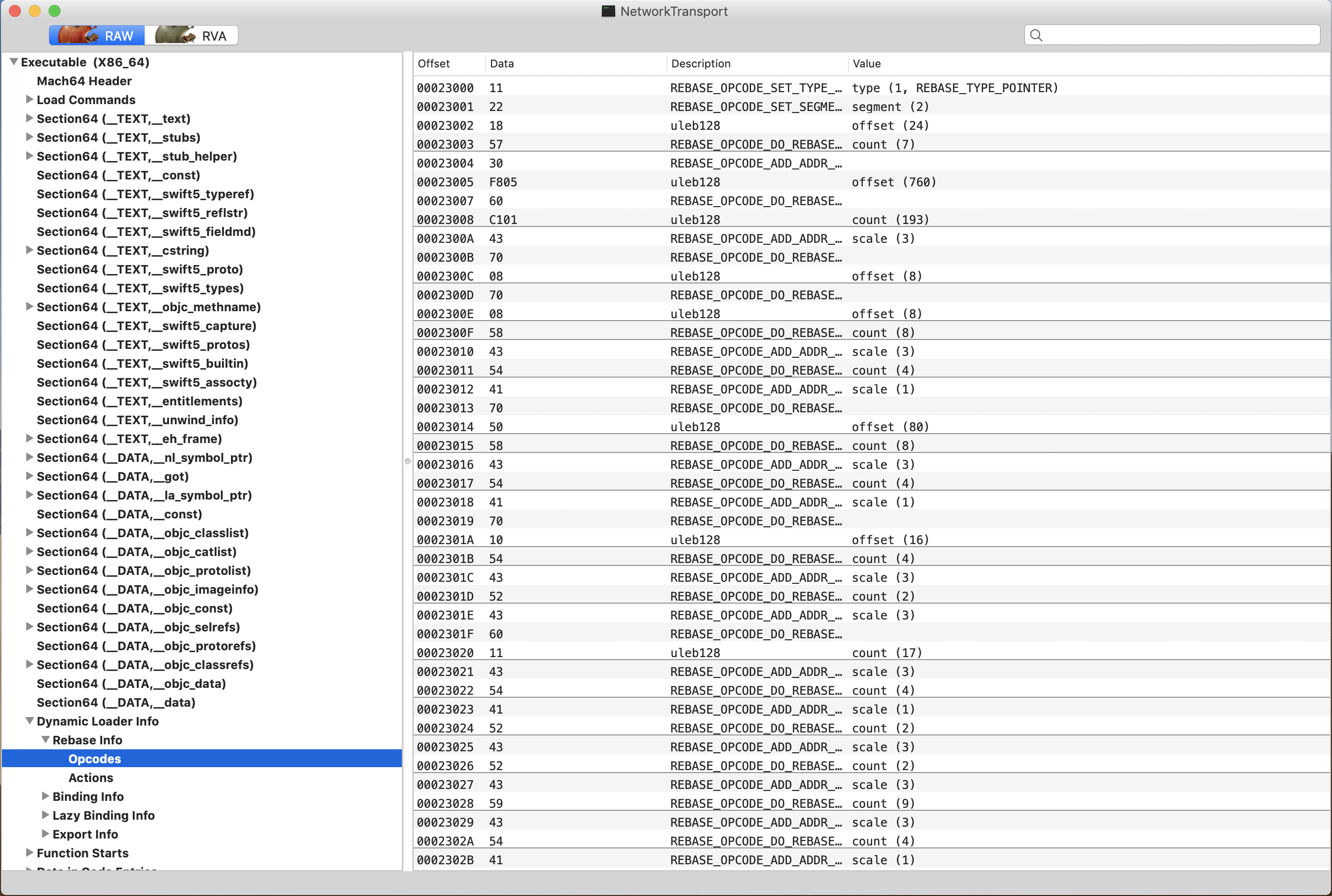
并且,当你展开Load Commands选项的时候,就会发现__LINKEDIT的段布局信息。
部分(Sections)
Section是段(Segment)中的子区域, 每个section包含的内容不同,大小也没有限制。例如在__TEXT segment里, __text section包含的是可执行的机器码; __cstring section包含C类常量字符串。值得注意的是,这里面的常量是没有重复的,原因是静态连接器在做构建的时候,合并了有相同值的常量。
PIC(Position Independ Code, code-gen)
在dyld拼接不同的dylibs的时候,dylib_A也需要知道如何调用dylib_B。但是由于每页都被签名的原因,dyld是无法直接去修改指令的。这时候code-gen,也就是动态PIC会在__DATA段为dylibA创建一个指针,指向dylibB的某个地址。比方说:dylibA想调用dylibB的sayHello方法,code-gen会先在Mach-O的__DATA段中建立一个指针指向sayHello,再通过这个指针实现间接调用。
dyld (dynamic loader/linker)
加载dylibs
dyld是iOS平台上的二进制加载器或者说动态链接器,也是内核的得力”小助手”。它负责将程序依赖的各种动态库加载到进程。同时也肩负着修复内部和外部指针指向的责任(传送门,dyld开源代码)。下面我们就来看看dyld是如何帮助内核完成加载工作的。
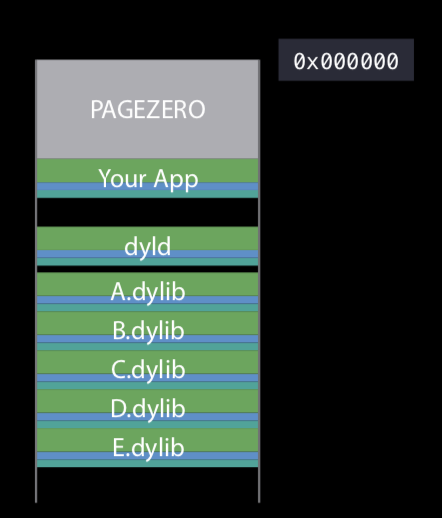
从上图可以看到,ALSR将dyld也加载到了进程中一个随机地址,此时的dyld和App享有同样的权限。其实从加载完dyld之后,内核要做的事情就结束了,之后的所有步骤都由dyld完成。首先,dyld会读取Mach-O文件中的指令(Load commands),去将其依赖的各个动态库映射到当前的逻辑地址空间,如果该动态库还依赖其他动态库,比方说下图的A库依赖C库,dyld会递归的将没加载过的dylib都加载到当前进程中(具体由ImageLoader完成),直到所有的动态库加载完毕。Apple官方称,一个App通常会加载1到400个dylibs! 不过幸运的是,这其中大部分是系统的dylibs,Apple在操作系统启动的时候,也已经帮我们提前计算和缓存了这些dylibs的信息,这样dyld加载它们的时候就会快很多。
Dirty & Clean Page
我们在上文提到: 当Copy-On-Write发生时,该page会被标记为dirty,同时会被复制。下面我们通过一个实例来进一步理解虚拟内存和Mach-O布局,以及dyld是如何产生出dirty page的。
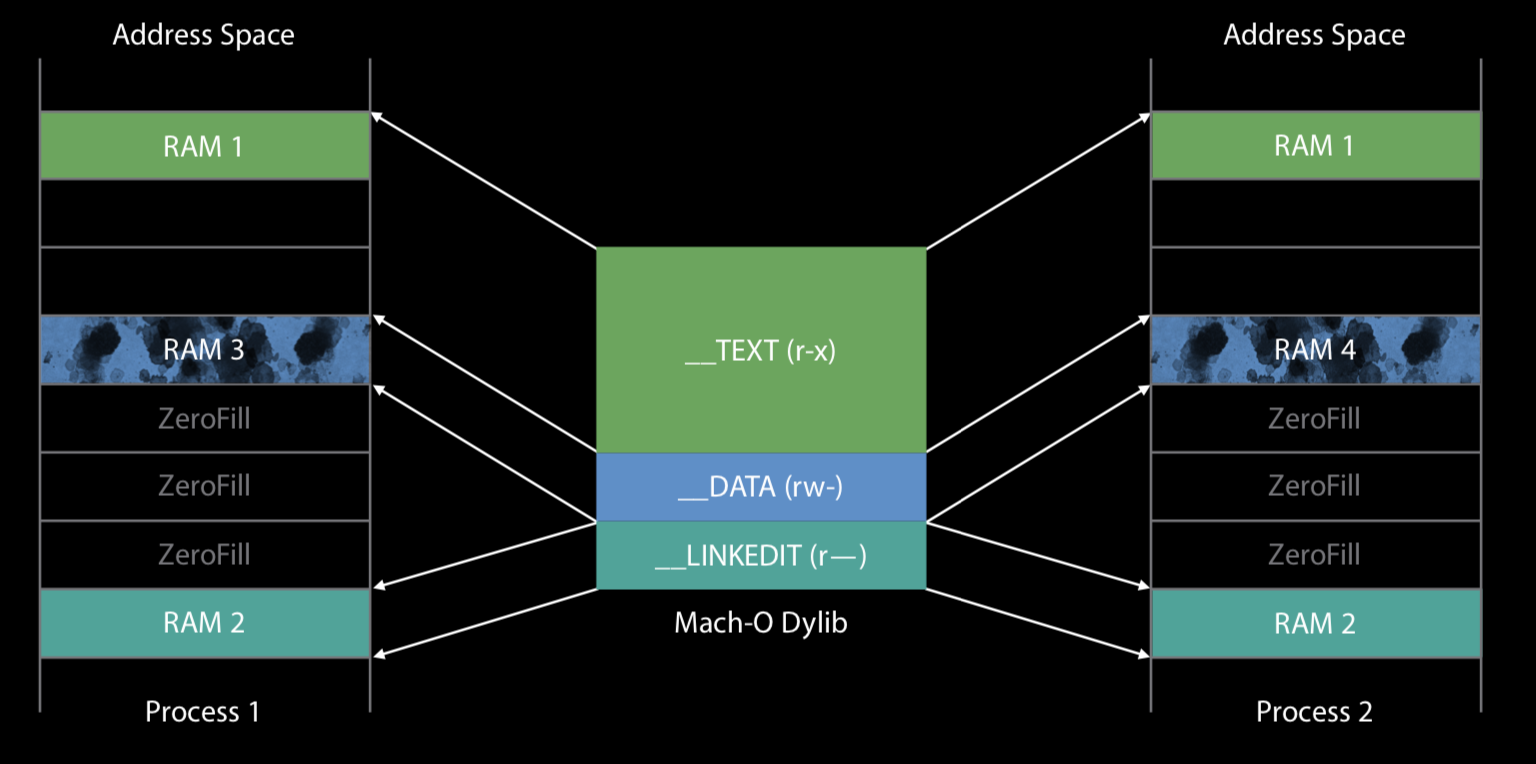
上图展示的是两个不同的进程共享同一个dylib的使用场景。我们从左到右看,左边的进程1先加载了该动态库,通过读取Load Commands, dyld知道要先加载__TEXT段(可读,可执行),上图__TEXT段大小为3个page,但是dyld只会先将第一个page映射到物理RAM。之后读取__DATA段信息(可读可写),在Mach-O章节中,我们已经知道,__DATA段存储了全局变量,而大部分的全局变量又都被初始化为0,所以在第一次被加载的时候,虚拟内存技术会将这些全局变量直接分配到一些page上(上图是3个page),不从磁盘中读取。接着dyld加载__LINKEDIT段,并将其映射到物理RAM2。当dyld加载__LINKEDIT(只读)段时,会被告知需要做一些”修正”以便dylib可以被顺利运行,这时,dyld就需要向__DATA段写入一些数据了。当写入发生时,该page对应的物理RAM就包含了当前进程信息,变成了dirty page。最终,这个dylib占用了8个page,包含2个clean page,一个dirty page(其余还未被映射)。
这时,如果有第二个进程同时引用了这个dylib,那么会发生什么呢?第一步同样是加载__TEXT段,不同的是,这次内核会发现在物理内存的某一处,已经加载过对应的__TEXT段,所以这次只是简单地把映射重定向下,不做任何IO操作。__LINKEDIT也是如此,区别就是这次变快了许多。当内核在寻找__DATA段的时候,它先会去检查是否还存在干净的副本,如果有,则直接映射;如果没有则需要重新从磁盘中读取,读取后dyld做修正,所以这个page也会变为dirty page。当dyld完成了修正过程后,__LINKEDIT也就不被再需要,内核可以在适当的时候释放其映射的物理RAM。
总结下: 当两个进程共享一个dylib时,使用虚拟内存技术映射物理RAM,把原本16个脏页面变成了两个脏页面和一个干净的共享页面。但上例是针对Apple自己提供的动态库,如果是我们自己写的cocoatouch framework,不排除当两个进程共用一个framework时,可以共享某些page。例如两个App都依赖Alamofire网络库时,一个App先行加载其Mach-O文件到物理内存;当另一个App加载Alamofire时,直接映射即可。
Rebase & Binding
这个步骤就是上文说到的”修正”步骤, 同时也用到了上文提到的PIC技术。Reabse是指修正内部指针指向; Binding是指修正外部指针指向。如下图所示: 指向_malloc和_free的指针是修正后的外部指针指向。而指向__TEXT的指针则是被修复后的内部指针指向。
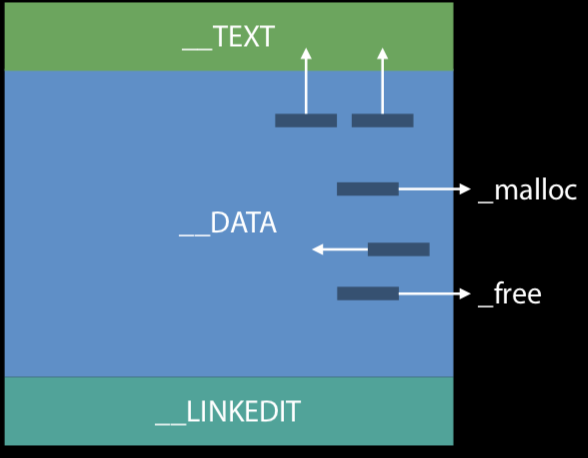
这个步骤发生的原因我们上文提到过: ASLR。由于起始地址的偏移,所有_DATA段内指向Mach-O文件内部的指针都需要增加这个偏移量, 并且这些指针的信息可以在__LINKEDIT段中找到。既然Rebase需要写入数据到__DATA段,那也就意味着Copy-On-Write势必会发生,dirty page的创建,IO的开销也无法避免。
Binding是__DATA段对外部符号的引用。不过和Rebase不同的是,binding是靠字符串的匹配来查找符号表的,虽说没有多少IO,但是计算多,比Rebase慢。
使用如下命令可查看所有Resabe和Binding的修复:
1 | xcrun dyldinfo -rebase -bind -lazy_bind NetworkTransport.app/NetworkTransport |
Objc Runtime
简介
Objective-C runtime是Objc这款语言的运行时函数库(传送门,Runtime开源代码),负责支持我们日常用到的各种动态特性,例如Target-Action,Associated Objects,Method Swizzling等。当然,功能觉不仅限于此,运行时库更像是一个桥阶层,帮助Objc和其他语言更好地协同工作。
Objc运行时库有很多的DATA数据结构,这些大都是系统类,这些系统类就会有很多的指针,例如指向其方法和超类。几乎所有的这些指针的修正都会在上一步完成。不过Objc runtime还需要做如下一些事情:
- 为每一个类生成一张函数表: 在Objc里我们可以使用字符串来初始化一个类,原理就是该类拥有函数表。
- 将分类(Category)里定义的扩展添加到函数表里: 如果分类override的原类的方法,则运行时会将其添加到函数表上方,调用时先用Category中定义的方法。
- 确保选择器的唯一性: 和上一个类似,Objc是依靠Selector的,所以确保其唯一性就保证了调用的正确性。
Load vs Initialize
在Objc时代,NSObject中有两个很特殊的方法: +load 和 +initialize,它们被用于类的初始化。
+load
当类或者是Category被添加到Objc Runtime时,+load方法即被调用。一个很典型的例子就是Method Swizzling,由于Apple “自底向上” 的初始化策略,当我们想替换系统的某个实现时,一般都会在自定义的类中重写+load方法,实现相关代码,已达到替换的目的。
- 父类+load方法 先于 子类+load方法执行;
- 主类+load方法 先于 Category的+load方法执行;
- 不同类+load方法调用顺序不确定。
下面我们来看看部分和+load方法相关的Objc runtime的源码,以加深对+load的理解。首先是文件objc-runtime-new.mm 中的 prepare_load_methods(header_info *hi) 函数:
1 | void prepare_load_methods(const headerType *mhdr) |
这个函数是将那些实现了+load方法的类和Category找出并实现(realized), 之后将其加入对应的loadable列表。其中
_getObjc2NonlazyClassList 和 _getObjc2NonlazyCategoryList 两个方法就是找出这样的类和Category。Non lazy意味着它们实现了+load方法,与之对应的则是lazy class,它们没有实现+load方法,所以不会在App启动的时候初始化,而是在收到第一次消息时初始化,可谓名副其实的懒加载。Mach-O的non lazy类可以在__DATA, __objc_nlclslist部分看到。
1 | static void schedule_class_load(Class cls) |
prepare_load_methods中还调用到了schedule_class_load方法,在该方法里第9行我们可以看到: 函数对传入参数的父类进行了递归调用,以确保父类优先的顺序。
当类和Category准备好后,Objc runtime就可以对它们的+load方法调用了。打开文件objc-loadmethod.m,找到其中的call_load_methods函数。
1 | void call_load_methods(void) |
这个函数有两点值得注意:
- 第12行和第26行的auto release pool操作,这意味着我们在自定义+load方法是不需要自己添加autorelease的block,Objc runtime帮我们处理了。
- 第17行和第21行,类的+load先于Category调用。
我们来看下call_class_loads的实现,call_category_loads方法和它异曲同工,就不详细介绍了。
1 | static void call_class_loads(void) |
最关键的在第21行: (*load_method)(cls, SEL_load)。这意味着+load方法的调用不是我们熟知的 objc_msgSend(消息机制),而是直接使用其内存地址的方式调用。这也意味着,父类、子类和分类中的+load方法的实现是被区别对待的。如果子类实现+load方法而父类没有实现,则父类中的+load方法不会被调用;如果主类和分类都实现了+load方法,则两个都会被调用,不过Category的+load方法会后调,这也为我们实现Swizzling提供了契机。
+initialize
+load方法在Swift中已经被废弃, 官方推荐使用+initialize来完成之前在+load中完成的事情。+initialize方法会在类或其子类收到第一条消息(方法调用)前调用。属于懒加载,节省系统资源,避免浪费。
Swift3.1废弃了该方法, 不过可以用Objc的Category做该Swift类的扩展,依旧可以使用该函数;纯Swift环境下也有替代方法,会在之后的文章中介绍。
打开objc-runtime-new.mm文件,找到lookUpImpOrForward方法:
1 | IMP lookUpImpOrForward(Class cls, SEL sel, id inst, |
当调用某个类的方法时,Objc runtime会使用这个函数去查找或者转发该消息。如果该类没有被初始化,则调用_class_initialize方法来初始化。
1 | void _class_initialize(Class cls) |
第12行的递归调用保证了父类先于子类初始化;第21行调用callInitialize,代码如下:
1 |
|
可以看出+initialize方法的调用和普通函数调用一样,走的都是发送消息的流程。也就是说,无论如何,父类的+initialize都会被调用,而且如果Category实现了+initialize方法,则会”覆盖”掉主类的+initialize方法(Category的实现在函数表中优先于主类)。
而且还带来一个问题: 如果子类没有实现+initialize方法,那么父类的+initialize方法会被调用多次。如果想确保自己的+initialize方法只执行一次的话,有两种方式:
- 判断当前Class是否是该类
- 使用dispatch once token(和初始化一个Singleton一样)
BTW, 无论是+load还是+initialize,都不需要在自己的实现里调用super load或者是super initialize。
Main函数的调用
dyld调用UIApplicationMain()。
总结下: 内核加载App和dyld到进程中,dyld加载所有依赖的dylibs,修正所有DATA page,之后Objc runtime初始化所有类,最后调用main函数。
如何优化App启动时间
熬过了理论部分,现在我们来看看如何将其应用到实际开发中,来提升我们App的启动速度。
Apple已有的优化
Apple的dyld 3(目前使用版本)与之前的dyld 2相比有了显著的优化。dyld 3由三个部分构成:
- 进程无关的Mach-O解析器
- 进程相关的启动回调引擎
- 启动回调缓存服务
启动回调(Launch Closure)是dyld 3引进的一个新概念,它是指启动你App所有的必要信息。比方说: 你的App用到哪些动态库,指针偏移量,代码签名位置等等。
在dyld 2时代,所有我们之前提到的启动步骤都是发生在内核分配给你的进程中的(in-process); 而在dyld 3中,关于Mach-O文件的解析发生在App第一次安装或者是之后的更新过程中。解析过后,关于App启动的信息会被存到磁盘的某处,供App启动时使用。这两步大大提升了App加载的速度,系统库是有共享缓存的,所以加载速度不会慢,但我们自己App中也会有很多依赖库,每次根据@rpath查找,映射也是很耗时的工作,而且从App下载之后,这些依赖库也不会再变了,把它们放到out of process中实为明智之举。
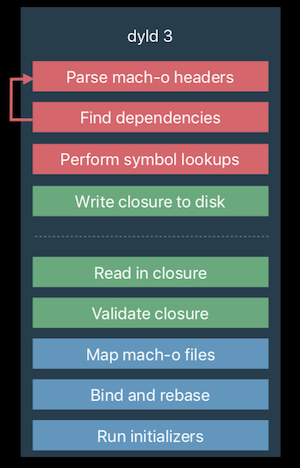
上图中虚线以上部分就是App第一次下载或更新时dyld会做的事情。虚线以下就是当App加载到进程中后dyld会做的事情, 除了需要从缓存中读取和验证信息之外,其他步骤都是一样的。
Apple为什么要这样做?除了我们已经提到的性能优化,还有两个主要原因: 安全和可靠性。先说可靠性: 将这些步骤移出进程意味着dyld的大部分工作就像是一个普通的守护程序,Apple的工程师可以用标准工具去测试它,提升可靠性;至于安全性,Apple认为最容易被攻击的步骤是解析Mach-O头部和查询依赖库。攻击者可以搞乱App的@rpath路径,或者替换为其它library来完成
@rpath confusion attacks. 所以Apple将其放入守护进程中加载。除此之外,符号表查找是另一项耗时工作,也完全可以放在进程外执行。因为除非更新软件和修改依赖库,否则该依赖库的符号表的内部偏移量是不会变的。
项目优化
在优化之前,我们需要知道如何测量启动时间,为什么启动时间会慢以及多长时间的启动时间是可被接受的。
推荐的启动时间
Apple推荐的启动时间是400ms, 当然最好是在App支持的最低配设备上达到这个标准。最长不要超过20s,否则系统会直接kill掉这个App。
如何测量启动时间
Apple提供一个内置的环境变量来记录App启动时间(pre-main): DYLD_PRINT_STATISTICS。 具体配置方法如下:
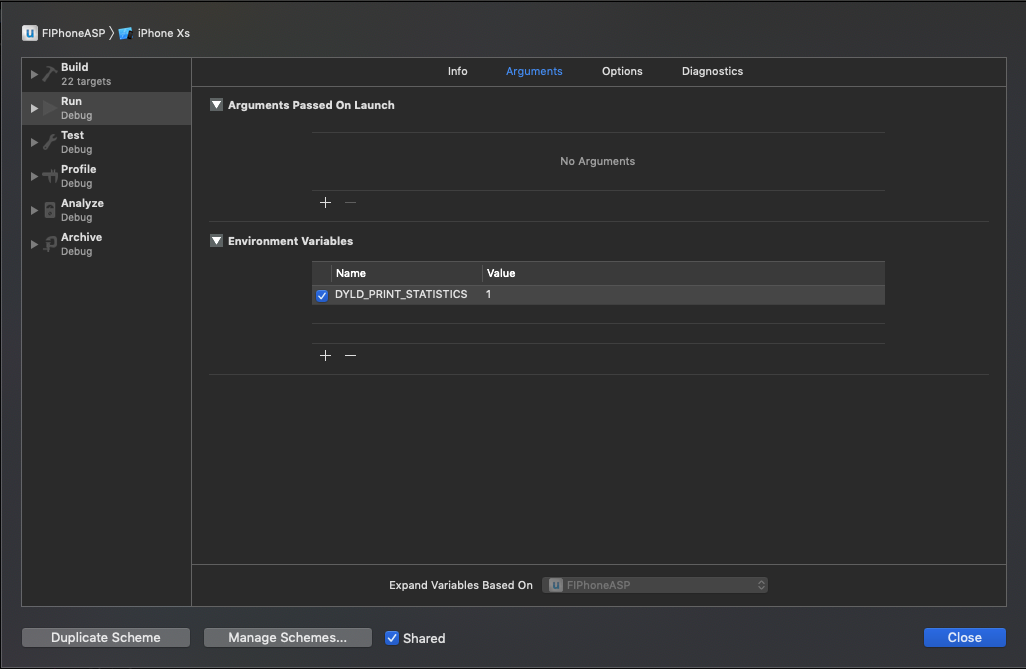
之后启动App,在console中就可看到如下信息:
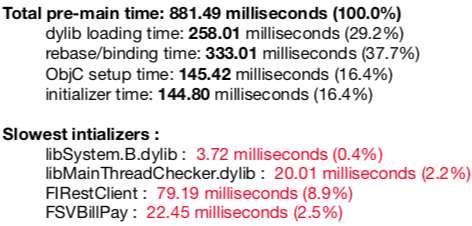
值得一提的是: dyld很智能,它会自动扣除Debugger的插入时间,所以不用担心Dev版本时间与发布版本不同。
优化启动时间
基于上文的console信息,我们的优化可以从4个方面来开始:
第一: 减少动态库的依赖。在iOS平台下,尽量减少项目所依赖的动态库; 如果无法减少,尝试将不同动态库合并。在项目开发阶段,有些程序员偏爱创建CocoaTouch Framework,觉得分离出业务逻辑以及依赖资源对开发和以后维护都有好处。但是,当这样做的时候,也需要考虑下App的启动时间以及性能,是否值得这样做。Apple的WWDC2016(Session 406)给出了一个例子: 一个项目依赖26个动态库,dylibs加载时间是240毫秒; 当将其合并成2个动态库时,加载时间变为20毫秒,可以说性能显著提高。
第二: 减少指针的使用。从上图中我们可以发现, rebase和binding的时间占据了最多的时间消耗。也就是说dyld修复指针指向花费了300多毫秒。从上文我们知道,dyld修复的指针都位于__DATA段,所以我们需要做的很简单,减少项目中指针的使用。如何减少? 如果你的项目使用纯Objc开发,那就要适当减少类的个数,根据WWDC2016(Session 406),Apple工程师的说法,项目中包含100,1000个类没什么太大的overhead,但要是5000到20000以上,则加载时间会多700到800毫秒。如果工程使用Swift居多,甚至是纯Swift,那么Apple建议能使用struct则使用struct,因为struct是值类型,不会引入指针(使用偏移量)。
第三: 优化Objc建立时间。这一步包含四个步骤:
- 注册类
- 更新类实例变量偏移(例如SDK更新)
- 注册Category
- 选择器的唯一性
这一步其实不用我们来优化,因为大部分的工作Apple已经帮我们做了,比方说ivar的偏移,这些会在rebase & binding步骤完成。
第四: 初始化。在iOS平台下,如果项目使用Objc编写,尽量少使用+load方法,如果非要使用, 替换为+initialize,延迟加载。如果项目已经使用Swift编写,那就没什么优化的了,Apple暗地里帮我们调用了他们自己的initializer(dispatch_once), 确保Swift class不会被初始化多次。
不过Apple给的启动时间的信息还是太少,除了前三步,最后一步其实是可以度量的。现在的iOS App很多都在使用Cocoapods或是Carthage加载第三方依赖库。如果我们想获得每一个这样的依赖库初始化耗时时间,该怎么做呢?简单说就是Swizzling +load方法加上Instrument Static Initializers工具来追踪时间消耗,具体步骤可以参考这篇文章: 如何精确度量 iOS App 的启动时间.
这篇文章大致介绍了下App启动的流程, 涵盖的知识点比较多,无法在有限的篇幅里面再扩展更多。今后的文章里会有针对某一个知识点的深入挖掘,敬请期待!
参考链接
Objective-C +load vs +initialize
从 dyld 到 runtime
App Startup Time: Past, Present, and Future
Optimizing App Startup Time
如何精确度量 iOS App 的启动时间